Il modo piů comune per pubblicare informazioni attraverso la rete č quello di utilizzare un server web, cioč qualcosa che consenta l'utilizzo del protocollo HTTP (HyperText Transfer Protocol).
Le informazioni pubblicate in questo modo sono rivolte a tutti gli utenti che possono raggiungere il servizio, nel senso che normalmente non viene richiesta alcuna identificazione. Al massimo si impedisce o si concede l'accesso in base al meccanismo di filtro gestito da inetd e tcpd.
Per offrire un servizio HTTP occorre un programma in grado di gestirlo. Di solito, si tratta di un daemon HTTP.
Analogamente al servizio FTP anonimo, il server HTTP consente l'accesso ad una particolare directory e alle sue discendenti. Si tratta in pratica di una sorta di directory home degli utenti che accedono attraverso questo protocollo.
Un server HTTP non offre solo un servizio di semplice ``consultazione'' di documenti: permette anche di ``interpellare'' dei programmi. Questi programmi sono normalmente collocati al di fuori della directory da cui si diramano i documenti HTML, per evitare che questi possano essere letti. In questo contesto, tali programmi sono definiti gateway, e normalmente vengono chiamati ``programmi CGI'', o cgi-bin.
Apache č un HTTP server derivato da httpd di NCSA ed č in pratica il server web standard di Linux e di molte altre piattaforme.
httpd [<opzioni>]
httpd č il server Apache per la gestione del protocollo HTTP. Il programma (daemon) puň essere avviato da inetd, oppure in modalitŕ standalone. La scelta di avviarlo in modo indipendente da inetd č giustificabile se si vuole ottenere una rapida risposta alle richieste a questo servizio. In effetti, questo č il modo normale di organizzare un server HTTP.
Se si opta per il controllo da parte di inetd, il file /etc/inetd.conf dovrŕ contenere una riga simile a quella seguente.
http stream tcp nowait nobody /usr/sbin/tcpd /usr/sbin/httpd
<!> Nelle sezioni seguenti si fa sempre riferimento a una installazione in cui il servizio viene avviato in modalitŕ standalone.
-d <directory-root-del-server>
Permette di definire la directory che funge come punto di partenza per il servizio web che viene offerto. Questa č giŕ definita in fase di compilazione del programma, e il suo valore predefinito dipende dalla scelta di chi ha compiuto questa operazione. Attraverso questa opzione, si puň indicare in modo esplicito una posizione diversa.
-f <file-di-configurazione>
Permette di indicare in modo esplicito il file di configurazione che
httpd deve leggere ed eseguire prima di iniziare a gestire il suo
servizio.
Se il file viene indicato utilizzando un percorso relativo, se cioč manca la prima
barra inclinata che identifica la radice, si fa riferimento a una posizione
relativa che parte dalla directory server-root, ovvero quella
definibile con l'opzione -d.
Il valore predefinito di questa opzione, dipende dal modo in cui č stato compilato il programma. Normalmente si tratta del file httpd.conf collocato nella directory /usr/local/etc/httpd/conf/, oppure /usr/etc/httpd/conf/ oppure ancora /etc/httpd/conf/.
Apache, nella sua configurazione originale, utilizza una disposizione di file e di directory piuttosto ``strana'' dal punto di vista della logica di Linux. Fortunatamente, le distribuzioni Linux che forniscono Apache giŕ inserito nel sistema, non rispettano questa organizzazione, e ne utilizzano una piů confacente con la gerarchia standard di Linux.
Di seguito viene descritta questa disposizione, indicando anche la possibile alternativa di un tipico sistema Linux.
ServerRoot. La directory a partire dalla quale si distribuiscono tutti i file piů importanti del servizio HTTP.
DocumentRoot. La directory a partire dalla quale si distribuiscono i documenti HTML.
La directory contenente i file di configurazione di Apache.
-bin/ /home/httpd/cgi-bin/La directory contenente i programmi CGI.
La directory contenente i file di log.
Di solito, non occorre configurare nulla per vedere funzionare il server, vale comunque la pena di dare una occhiata ai file di configurazione contenuti in /etc/httpd/conf/ e di modificare qualche dato prima di presentarsi all'esterno con il proprio servizio web.
Si tratta normalmente dei file:
Come al solito, non conviene toccare i file originali.
Per questo, la distribuzione originale di Apache fornisce i file
httpd.conf-dist, srm.conf-dist e
access-dist che devono essere copiati in modo da ottenere i nomi
elencati precedentemente.
Il file di configurazione httpd.conf contiene in particolare le direttive seguenti.
---------
ServerType { standalone | inetd }
Permette di informare Apache sul modo in cui questo viene avviato: in modalitŕ standalone o attraverso inetd.
Port <numero-porta>
Si tratta dell'indicazione della porta (di solito č 80 corrispondente ad http), necessaria nel caso in cui il daemon sia stato avviato in modalitŕ standalone. Infatti, diversamente, č inetd a stare in ascolto della porta corrispondente al servizio http.
HostnameLookups { on | off }
Permette di decidere se si intende registrare nei file di log il numero IP o il nome degli host che accedono al servizio. Attivando questa direttiva (on) si registrano i nomi corrispondenti.
User <utente>
Group <gruppo>
Permette di abbinare un utente e un gruppo agli accessi effettuati attraverso il protocollo HTTP. In pratica, quando si legge un file HTML o si interpella un programma CGI, lo si fa come se si fosse l'utente indicato da queste due direttive. Solitamente si utilizza l'utente e il gruppo nobody.
ServerAdmin <e-mail>
L'indirizzo e-mail dell'amministratore del servizio.
ServerRoot <directory>
Rappresenta la directory a partire dalla quale si diramano le informazioni sulla configurazione, sul log e simili. Corrisponde solitamente a qualcosa come .../etc/httpd/.
ErrorLog <log-degli-errori>
TransferLog <log-dei-trasferimenti>
RefererLog <log-dei-riferimenti>
AgentLog <log-degli-http-agent>
Definiscono i nomi e la collocazione dei file di log.
PidFile <file-pid>
Definisce il nome e la collocazione del file utilizzato per contenere il numero di processo del daemon.
ScoreBoardFile <file-di-informazioni>
Definisce il nome e la collocazione di un file contenente una serie di informazioni sul funzionamento corrente del server.
MaxClients <numero-massimo-di-client>
Definisce il numero massimo di programmi client che possono accedere in uno stesso istante.
Il file di configurazione srm.conf contiene in particolare le direttive seguenti.
---------
DocumentRoot <directory-root-html>
Rappresenta la directory da cui si possono diramare i documenti HTML.
UserDir <percorso-root-utenti>
Rappresenta un percorso aggiuntivo nel caso si acceda a un utente utilizzando il nome dell'utente stesso preceduto dal simbolo tilde (~). Supponendo di avere una dichiarazione del tipo
UserDir public_html
se si accede all'indirizzo www.zigozago.dg/~daniele/elenco.html si fa effettivamente riferimento al file ~daniele/public_html/elenco.html. In questo modo si evita di esporre l'intera directory home dell'utente.
DirectoryIndex <file-indice>...
Quando si accede a una directory invece che a un file specifico, se questa contiene un file tra quelli elencati nella direttiva DirectoryIndex viene restituito quel file, invece del semplice elenco del contenuto. Solitamente si utilizza il nome index.html. Questo meccanismo permette di mascherare il contenuto effettivo della directory, oltre che di guidare l'utente del servizio in modo che non si perda in una miriade di file.
IndexIgnore <modello-da-ignorare>...
Quando si consente di accedere a una directory visualizzandone il contenuto (perché manca il file index.html o equivalente), si puň fare in modo che alcuni file non appaiano in elenco. Utilizzando questa direttiva, si possono indicare i modelli di file da non includere. Per questo si possono usare i consueti caratteri jolly (punto interrogativo e asterisco).
DefaultType <MIME-type>...
Permette di definire il tipo MIME predefinito di un documento per il quale non si riesca a determinare il tipo nel modo normale, cioč in base all'estensione. Di solito, questo valore predefinito č text/plain
Alias <directory-fasulla> <directory-reale>
Questo tipo di direttiva, che puň essere ripetuta, permette di definire delle directory in posizioni diverse da quelle reali. La directory ``fasulla'' fa riferimento a una directory indicata nell'indirizzo richiesto e quella reale indica la directory effettiva nel filesystem. Per esempio,
Alias /icons/ /home/httpd/icons/
fa in modo che l'indirizzo www.zigozago.dg/icons/ faccia in realtŕ riferimento alla directory /home/httpd/icons/ e non alla directory /icons/ discendente da DocumentRoot.
ScriptAlias <directory-fasulla> <directory-reale>
Funziona come la direttiva Alias, ma si riferisce ai programmi CGI.
Il file di configurazione access.conf permette di controllare in qualche modo gli accessi. La sua configurazione č piů complessa rispetto a quella degli altri file. In particolare, oltre a normali direttive, si utilizzano dei delimitatori simili a tag HTML che permettono di definire il contesto a cui si riferiscono le direttive contenute.
Gli esempi seguenti rappresentano il contenuto normale di questo file.
---------
<Directory /home/httpd/html>
Options Indexes Includes ExecCGI
AllowOverride None
order allow,deny
allow from all
</Directory>
Si tratta delle dichiarazioni riferite alla directory /home/httpd/html/, ovvero quella definita in precedenza come DocumentRoot. In pratica vengono consentiti tutti gli utilizzi normali e l'accesso da parte di chiunque.
---------
<Directory /home/httpd/cgi-bin>
AllowOverride None
Options None
</Directory>
Si tratta delle dichiarazioni riferite alla directory /home/httpd/cgi-bin/,
ovvero quella destinata a contenere i programmi CGI.
Non viene definita alcuna opzione.
---------
<Location /status>
SetHandler server-status
order deny,allow
deny from all
allow from topolino.zigozago.dg
</Location>
Si tratta delle dichiarazioni riferite al servizio di informazioni sullo stato del server. Se queste istruzioni non sono commentate, permettono di visualizzare lo stato del server attraverso un normale accesso. Nell'esempio, viene concesso al computer topolino.zigozago.dg di accedere al file /status in modo da ottenere queste informazioni.
L'elenco seguente č un esempio di ciň che puň essere ottenuto in questo modo.
Apache Server Status for topolino.zigozago.dg
Current Time: Sun Sep 28 14:00:47 1997
Restart Time: Sun Sep 28 14:00:28 1997
Server uptime: 19 seconds
Total accesses: 0 - Total Traffic: 0 B
CPU Usage: u0 s0 cu0 cs0
0 requests/sec - 0 B/second -
Scoreboard:
K___W__...........................................
..................................................
..................................................
Key:
"_" Waiting for Connection, "S" Starting up,
"R" Reading Request, "W" Sending Reply,
"K" Keepalive (read), "D" DNS Lookup, "L" Logging
2 requests currently being processed, 5 idle servers
Srv PID Acc M CPU SS Conn Child Slot Host Request
0 8449 0/0/0 K 0.00 10 0.0 0.00 0.00
4 8453 0/0/0 W 0.00 0 0.0 0.00 0.00 topolino.zigozago.dg GET /status HTTP/1.0
------------------------------------------------------------------------
Srv Server number
PID OS process ID
Acc Number of accesses this connection / this child / this slot
M Mode of operation
CPU CPU usage, number of seconds
SS Seconds since beginning of most recent request
Conn Kilobytes transferred this connection
Child Megabytes transferred this child
Slot Total megabytes transferred this slot
Avviando il proprio web browser preferito e selezionando un indirizzo HTTP corrispondente al nome o all'indirizzo del proprio computer, si dovrebbe vedere la pagina introduttiva della documentazione di Apache.
Il capitolo `Introduzione a HTML' introduce alla realizzazione di pagine HTML.
Per altre notizie sull'uso e il funzionamento di Apache, conviene visitare l'indirizzo http://www.apache.org.
Per poter usufruire di un servizio HTTP occorre un cosiddetto browser o navigatore web. Il tipico programma di questo tipo dovrebbe consentire anche la visualizzazione di immagini, ma un buon programma che utilizza un semplice terminale a caratteri puň essere utilizzato in qualunque condizione e per questo, tale possibilitŕ non deve essere scartata a priori.
Di fatto, il tipico client HTTP non si limita ad utilizzare questo protocollo, ma ne permette anche l'utilizzo di altri, tipicamente FTP. In generale, quando si fa riferimento a questo genere di programmi, sarebbe meglio parlare di client integrati.
L'integrazione di diversi protocolli impone l'utilizzo di un sistema uniforme per indicare gli indirizzi, in modo da conoscere subito in che modo si deve effettuare il collegamento. Per questo, quando si utilizza un navigatore web, si devono usare indirizzi espressi in modo standard, e precisamente secondo il formato URL, o Uniform Resource Locator. Attraverso questa modalitŕ, č possibile definire tutto quello che serve per raggiungere una risorsa: protocollo, host, porta, percorso. Il formato generale di un URL č il seguente.
<protocollo><indirizzo-della-risorsa>
Il protocollo puň essere indicato in uno dei modi seguenti.
Quando si vuole fare riferimento a un file locale senza utilizzare alcun protocollo particolare, si puň indicare anche il nome file:.
L'indirizzo della risorsa viene espresso in maniera differente a seconda del protocollo. Nel caso particolare di HTTP e FTP, e anche per i file locali, si utilizza il formato seguente.
<dominio>[<porta>]<risorsa>
http://www.zigozago.dg:8080/esempi/indice.html
http://www.zigozago.dg/esempi/indice.html
Come nell'esempio precedente, ma senza l'indicazione della porta che questa volta corrisponderŕ al valore predefinito, cioč 80.
http://192.168.1.1/esempi/indice.html
Come nell'esempio precedente, ma l'indicazione del computer host avviene per mezzo del suo indirizzo IP invece che attraverso il nome di dominio.
ftp://ftp.zigozago.dg/pub/archivi/esempio.tar.gz
file://localhost/home/daniele/indice.html
In questo caso si vuole fare riferimento a un file locale. Precisamente si tratta del file /home/daniele/indice.html contenuto nel computer localhost.
Di solito, i navigatori web permettono di accedere ai file locali in modo meno formale, indicando semplicemente il percorso del file.Questo tipo di indicazione č particolarmente utile quando si vuole fare riferimento ad una pagina indice o iniziale.
Un problema che riguarda un po' tutti i programmi client, sono i tempi morti. Questi programmi, quando tentano di accedere a un risorsa senza riuscirci, restano a lungo in attesa prima di restituire una segnalazione di errore. Se si utilizza, o si gestisce, un DNS server e questo non risulta raggiungibile, oppure a sua volta non riesce a raggiungere gli altri DNS server di livello superiore, le attese sono dovute al ritardo nella risposta nella risoluzione dei nomi.
La maggior parte dei navigatori, all'avvio cercano di raggiungere la loro home page e questo richiede un collegamento in funzione in quel momento.
Quando si vuole utilizzare un programma del genere semplicemente per delle attivitŕ locali, e si notano questi problemi nelle risposte, se si gestisce un DNS server locale che, almeno temporaneamente non ha accesso alla rete esterna, si puň provare a disattivarlo, utilizzando il comando seguente.
# ndc stop
In seguito, per riattivarlo, basterŕ utilizzare il comando opposto.
# ndc restart
Lynx č la prova di ciň che puň fare un buon programma per i terminali senza grafica, anche per la navigazione del web. A prima vista puň risultare complicato da utilizzare, ma il tempo necessario per imparare il suo funzionamento sarŕ ripagato.
Lynx č un navigatore web completo, a parte la limitazione dovuta alla mancanza della grafica. Č stato portato su un gran numero di piattaforme, Dos inclusa ( `DosLynx'). La sua semplicitŕ lo rende prezioso in tutte quelle situazioni in cui non č possibile utilizzare il sistema grafico X Window System.
Prima di avviare Lynx la prima volta, conviene controllare il suo file di configurazione generale. Molto probabilmente converrŕ modificare qualcosa. Si tratta di lynx.cfg che potrebbe trovarsi in /usr/lib/, oppure in /etc/.
Vale la pena di cambiare alcune cose: l'indicazione della pagina iniziale, la posizione della guida e della pagina indice. Infatti, in questi casi, si fa riferimento a pagine HTML in rete, mentre č normale che ognuno si crei una propria pagina di inizio e che si abbiano a disposizione anche localmente i file della guida.
Queste indicazioni potrebbero apparire come negli esempi seguenti.
STARTFILE:file://localhost/etc/lynx-inizio.html
HELPFILE:file://localhost/usr/doc/lynx-2.6-2/lynx_help/lynx_help_main.html
DEFAULT_INDEX_FILE:file://localhost/etc/lynx-indice.html
In tutti i casi, si fa riferimento a un file nel computer locale, localhost.
Nel primo caso si fa riferimento al file /etc/lynx-inizio.html,
nel secondo a /usr/doc/lynx-2.6-2/lynx_help/lynx_help_main.html, e nel
terzo a /etc/lynx-indice.html.
Probabilmente, tutto il resto puň essere lasciato com'č.
lynx [<opzioni>] [<file-iniziale>]
lynx č il programma client che consente in particolare di utilizzare il protocollo HTTP. Puň essere avviato in particolare con l'indicazione di un indirizzo iniziale (di solito una pagina), espresso secondo lo standard URL (Uniform Resource Locator) oppure puň trattarsi semplicemente di un file espresso senza particolari formalitŕ. Se non č indicato alcun file iniziale, viene utilizzato quanto specificato nella configurazione contenuta nel file lynx.cfg, alla voce STARTFILE.
-anonymous
Una particolaritŕ di Lynx č la possibilitŕ di concedere un numero limitato di funzionalitŕ ad utenti occasionali. Con questa opzione, si fa in modo che Lynx possa essere utilizzato solo come strumento di lettura ipertestuale, eliminando ogni possibilitŕ di salvataggio di pagine o di dati e di stampa. Puň essere molto utile in quelle situazioni in cui si vuole concedere l'utilizzo del programma ad utenti non controllati e senza account.
-cfg=<file-di-configurazione>
Permette di definire il file di configurazione, quando non si vuole utilizzare quello predefinito corrispondente a lynx.cfg.
-ftp
Disabilita l'utilizzo del protocollo FTP.
-homepage=<indirizzo-URL>
Permette di indicare una homepage differente dalla pagina iniziale. Verrebbe utilizzata in particolare quando si accede alla pagina principale (main).
-index=<indirizzo-URL>
Permette di indicare una pagina indice.
-localhost
Impedisce l'accesso a indirizzi URL esterni al computer locale. In pratica, obbliga a rimanere all'interno del computer locale.
-term=<terminale>
Normalmente, Lynx č in grado di determinare da solo il tipo di terminale a disposizione, in modo da potervisi adattare. A volte, questo riconoscimento non avviene correttamente, e in quei casi č necessario indicare espressamente il nome del terminale. Se utilizzando una console Linux, o una finestra sotto X Window System non si distingue il cursore, conviene provare indicando un terminale vt100.
$ lynx -term=vt100 file://localhost/home/daniele/indice.html
Avvia Lynx specificando il tipo di terminale (vt100) e il file iniziale.
$ lynx
Avvia Lynx utilizzando esclusivamente la configurazione contenuta nel file lynx.cfg.
Vedere lynx(1).
Lynx permette l'utilizzo di una serie di comandi abbinati a tasti piů o meno mnemonici. Non č disponibile un menu, quindi occorre un minimo di preparazione prima di poter utilizzare Lynx.
L'abbinamento tra i comandi e i tasti corrispondenti č definito all'interno del file di configurazione (lynx.cfg), ma in generale, conviene non alterare le definizioni predefinite.
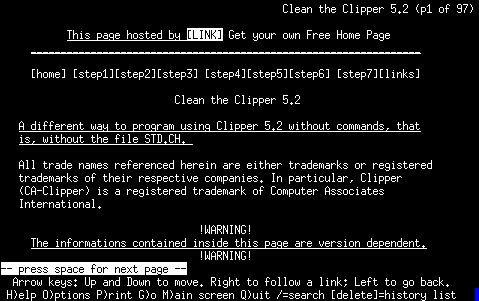
La figura (figura) mostra in che modo si presenta Lynx dopo essere stato avviato con l'indicazione di una pagina HTML particolare. Nelle ultime righe dello schermo (o della finestra) appare un riepilogo dei comandi principali. Prima di richiamare la guida (help) conviene aver configurato correttamente il file lynx.cfg al riguardo: molto probabilmente, i file della guida sono disponibili localmente, mentre di solito, questo file fa riferimento alla guida ottenibile attraverso la rete. Nella sezione dedicata alla configurazione č giŕ stato spiegato come fare per correggere questo particolare.
La navigazione all'interno di un documento ipertestuale č relativamente semplice,
anche se non si puň utilizzare il mouse.
In particolare va ricordato l'uso dei tasti freccia, per cui
Lynx mantiene la traccia dei riferimenti attraverso cui si č giunti al documento
attuale,
Un'altra cosa importante č la possibilitŕ di ottenere un elenco compatto di
tutti i riferimenti contenuti nel documento attualmente visualizzato.
Ciň si ottiene con il comando LIST corrispondente al tasto
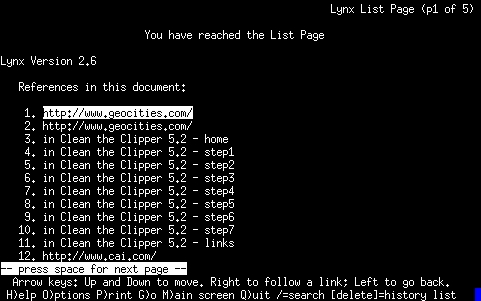
La tabella (seguente) mostra l'elenco dei comandi utili per la navigazione di un documento ipertestuale.
Il documento visualizzato puň essere salvato o stampato in vari modi.
Il comando di stampa viene richiamato utilizzando il tasto
Lynx, quando carica un documento, lo trasforma immediatamente nel formato da visualizzare.
Per ottenere il sorgente di quel documento occorre ripetere l'operazione di
caricamento senza alcuna trasformazione.
Questo si ottiene con il tasto
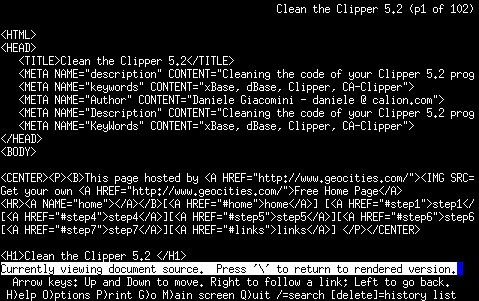
Un documento, o piů in generale un file, puň essere caricato nella sua
forma originale, normalmente per poterlo salvare.
Questo si ottiene con il comando DOWNLOAD normalmente abbinato al tasto
Con il comando OPTIONS normalmente richiamabile con il tasto
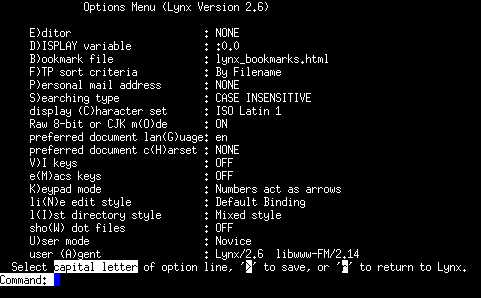
I riferimenti (link) piů importanti possono essere salvati in un file apposito. Il nome e la posizione di questo file č definito nel file di configurazione lynx.cfg e comunque puň essere cambiato con il menu di configurazione appena descritto sopra.
Per salvare un riferimento nel ``segnalibro'', o bookmark, si utilizza il
comando ADD_BOOKMARK normalmente collegato al tasto
Per richiamare l'elenco dei riferimenti salvati, si utilizza semplicemente il tasto
Il funzionamento di Lynx viene concluso con il comando QUIT,
Lynx, anche se non sembrerebbe, č un programma complesso e molte delle sue potenzialitŕ non sono state descritte. Lynx č normalmente accompagnato da una buona documentazione interna che vale la pena di leggere.
Oltre a Lynx sono disponibili molti altri tipi di client HTTP. In particolare, Arena e Grail potrebbero essere una valida alternativa essendo programmi che utilizzano la grafica e quindi si avvalgono di X Window System.
Grail, nella versione 0.3b2, č concesso in licenza da CNRI (Corporation for National Research Initiatives) a condizioni piuttosto strane: ... While Licensee may share the Software within its organization or otherwise use it internally for the purposes specified herein, this Agreement does not authorize Licensee to distribute copies of the Software to the public, perform and/or display the Software publicly, or otherwise make the Software accessible to the public. Additional copies of the software may be obtained from CNRI. .... Probabilmente si tratta solo di un modo per evitare che si diffondano versioni incomplete, trattandosi ancora di un progetto in corso di sviluppo.Nell'ambito del software commerciale č disponibile Netscape che č descritto nella sezione `Netscape'.
1997.10.26 - Scritto da Daniele Giacomini daniele@calion.com (vedi copyright: Appunti Linux).